Feature Store Architecture: System Design and Implementation Considerations
Published on
by ![]() Gautham Vemulapalli
Gautham Vemulapalli
⏳ 7 min read
Machine learning infrastructure continues to evolve from ad-hoc, model-centric approaches to systematic, data-centric platforms. In this analysis, I’ll examine feature store architectures through the lens of my experience building the Ford “Mach1ML” Feature Store, a system designed to accelerate machine learning workflows from 6 months to 1 week.
The Feature Engineering Bottleneck
Feature engineering represents the most time-consuming aspect of the machine learning lifecycle. At Ford, we identified several key constraints:
- Data silos and access friction: Engineers spent disproportionate time discovering and accessing data
- Redundant transformations: Teams frequently recreated identical features
- Training-serving skew: Features engineered differently in training versus inference environments
- Lack of governance: No standardized approach to feature versioning or documentation
These constraints created a significant bottleneck that extended model development cycles to six months, severely limiting our ability to operationalize machine learning at scale.
Architectural Objectives
Our feature store system needed to address several core objectives:
- Feature reusability: Enable teams to discover and leverage features created by others
- Consistency: Ensure identical feature calculations between training and serving environments
- Performance: Provide low-latency access for real-time inference and efficient batch processing
- Governance: Maintain feature lineage, versioning, and access controls
These objectives translated into specific performance requirements:
- Training dataset generation: Join hundreds of features across 10M+ rows in under a few hours
- Feature retrieval latency: Serve query results in under 500ms for exploration
- Inference latency: Provide features for real-time inference in under 50ms
- Availability: Maintain 99.99% uptime for feature serving infrastructure
Core System Components
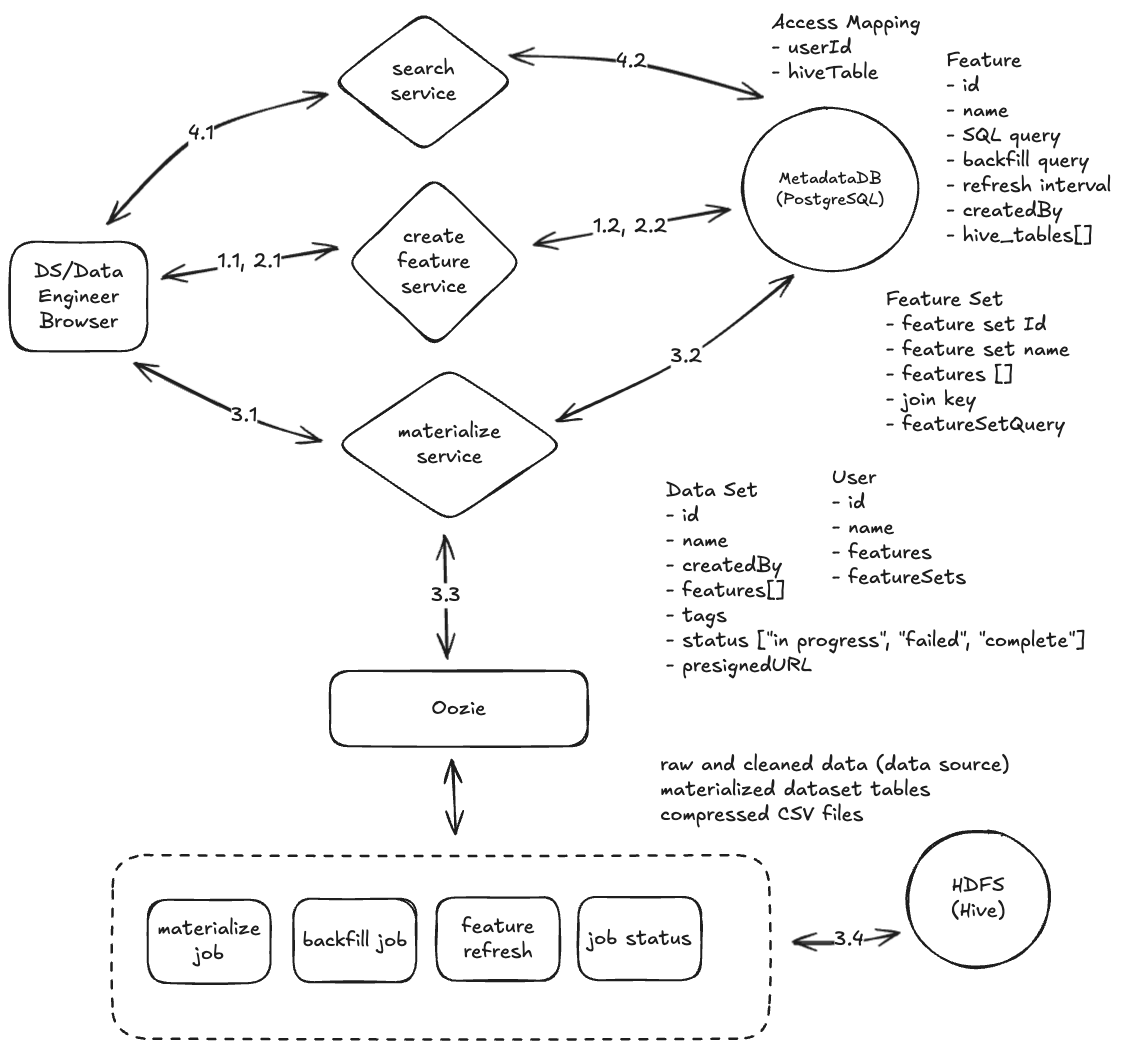
Our feature store architecture consisted of several interconnected components:
1. Metadata Repository (Relational DB)
The metadata layer maintained information about features, their relationships, and lineage, enabling feature discovery, governance, and understanding without requiring access to underlying data.
2. Feature Definition System
The feature definition component allowed engineers to define transformation logic in a standardized way, typically using SQL:
-- Example feature definition
CREATE FEATURE vehicle_diagnostic_score AS (
SELECT
vehicle_id,
event_time,
AVG(sensor_reading) OVER (
PARTITION BY vehicle_id
ORDER BY event_time
ROWS BETWEEN 30 PRECEDING AND CURRENT ROW
) AS diagnostic_score
FROM vehicle_sensors
)
3. Feature Set Creation
The feature set creation service handled the grouping of related features for model training and inference, representing the model’s view of the feature data and ensuring consistent feature selection between environments.
4. Feature Set Materialization
The materialization component generated point-in-time correct datasets for model training by executing transformation logic, handling time-based aggregation, and optimizing computation for large datasets.
5. Feature Serving
The serving component provided low-latency access to feature values for inference, balancing latency requirements with consistency guarantees and resource efficiency.
Scaling Strategies
Several scaling strategies were applied to meet performance requirements:
1. Metadata-Only vs. Materialized Approaches
We faced a fundamental architectural decision of whether to materialize feature data or store only transformation logic:
Metadata-only approach:
- Advantages: Lower storage costs, always-fresh data, simpler data governance
- Disadvantages: Higher query latency, compute-intensive for large datasets
Materialized approach:
- Advantages: Lower latency, efficient scaling for inference
- Disadvantages: Storage overhead, potential for stale data
We implemented a hybrid approach based on access patterns:
- Compute cold features on-demand for cost efficiency, flexibility, and data freshness
- Materialize and cache hot features for fast real-time access, particularly for inference

2. Distributed Computation
For large-scale feature processing, we leveraged Apache Spark for several reasons:
- Parallel processing: Distributing transformation logic across compute nodes
- Optimization techniques:
- Broadcast joins for small-large table combinations
- Query planning for complex transformation chains
- Reduction of shuffle operations for join-heavy workloads
- Fault tolerance: Resilient distributed datasets (RDDs) for recovery from partial failures
This approach was particularly valuable for materializing large feature sets with complex joins where single-node computation would be prohibitively slow.
3. Caching Strategies
We implemented multi-level caching to improve performance:
- Feature value caching: Keeping frequently accessed features in memory
- Computation caching: Storing intermediate results for complex transformations
- Cache invalidation: Time-based policies based on feature refresh intervals
For feature set materialization, we implemented a check-before-compute approach:
- Check cache before starting materialization
- Pull from cache if available, compute only missing components
- Store newly computed features in cache for future use
Technical Challenges and Solutions
1. Authorization and Access Control
A major challenge was ensuring the feature store didn’t become a backdoor for data access:
- Challenge: Limited access to the Ranger authorization API for checking user permissions
- Solution: Implemented a workaround using nightly exports:
- Set up nightly exports of Ranger policies (JSON/XML) to HDFS
- Configured HDFS event notifications to detect policy changes
- Built an authorization service to parse policies and map them to the metadata database
- Integrated with Ford’s access request system (APS) for seamless permission requests
- Enhanced discovery: Provided de-identified/anonymized data previews so users could understand feature content before requesting access
2. Query Performance for Complex Joins
Feature materialization required joining large datasets:
- Challenge: Efficiently processing millions of rows across hundreds of features
- Solution: Leveraged Spark’s distributed computation with several optimizations:
- Process data in chunks using in-memory processing
- Apply optimized join algorithms to reduce computation time
- Implement broadcast joins for small features that could fit in memory
- Utilize Spark’s fault tolerance for long-running materialization jobs
- Result: Achieved materialization of complex feature sets within our time constraints
3. Real-time Feature Serving
Low-latency feature serving required specialized architecture:
- Challenge: Meeting sub-50ms response times with feature computation in under 20ms
- Solution: Implemented a multi-tiered serving architecture:
- Fast-path for cached features with sub-millisecond retrieval times
- Pre-computed aggregations for commonly used time windows
- Service-level agreements enforced through timeout mechanisms
- Read replicas of SQL Server to ensure fast metadata operations
- Result: Consistently met latency requirements while maintaining data freshness
Implementation Experience at Ford
Building the Ford Feature Store provided valuable insights into the practical challenges of implementing these architectural patterns in an enterprise environment with specific constraints.
Build vs. Buy Decision
A critical early decision was whether to build a custom solution or leverage existing platforms:
- Market evaluation: We assessed solutions like Google Feast, Tecton.ai, and Hopsworks
- Key constraints:
- Data privacy concerns necessitated maintaining data ownership on-premises
- Granular access control requirements exceeded capabilities of off-the-shelf solutions
- Authorization models of existing platforms didn’t align with Ford’s governance framework
- Hopsworks had limitations in its authorization model—access controls were at the feature store level rather than feature level
This led to the decision to build a custom feature store tailored to Ford’s specific requirements and infrastructure constraints.

Lessons Learned for Future Implementations
Through this implementation, several valuable lessons emerged that would influence future feature store designs:
1. Infrastructure Abstraction
The system was tightly coupled to the Hadoop/Hive ecosystem, creating future migration challenges:
- A more abstracted data access layer would have simplified future transitions to cloud-native solutions
- Storage-agnostic interfaces would enable seamless migration to systems like Snowflake or cloud data lakes
- Feature computation engines should be pluggable components rather than embedded dependencies
2. Cost Optimization
Post-implementation, we identified several cost-saving opportunities:
- Spot instances for batch processing could reduce infrastructure costs by 50% for materialization jobs
- Tiered storage strategies would better balance performance and cost for features with different access patterns
- More aggressive caching policies would reduce computational overhead for frequently accessed features
3. Search and Discovery Improvements
As the feature catalog grew beyond our initial expectations, we identified search limitations:
- Elasticsearch integration would provide more powerful and flexible feature discovery
- Faceted search capabilities would improve navigation of the large feature catalog
- Semantic search for feature descriptions would help users find relevant features more effectively
- Initially we underestimated the importance of discovery, assuming feature counts would remain manageable
4. Use Case Expansion
The initial focus on Marketing and Production Line Maintenance proved successful but limited:
- Earlier engagement with additional departments would have identified more high-value use cases
- Cross-functional feature sharing opportunities were missed due to the initial narrow focus
- Feature reuse potential was higher than initially estimated, with many features valuable across domains
5. Real-time Performance Optimization
For inference scenarios, we identified several performance optimizations:
- In-memory caching for latest feature values would significantly reduce latency
- Pre-materialization of complex features for real-time serving would improve predictability
- Specialized serving infrastructure for ultra-low-latency requirements would better support critical applications
- More comprehensive monitoring of feature serving latency to identify optimization opportunities
Conclusion
The Ford implementation demonstrated that even with enterprise constraints, significant acceleration of ML workflows is achievable through thoughtful feature store design. The most successful implementations balance flexibility and performance, providing fast access to feature data while maintaining adaptability as organizational requirements evolve.
The key to success lies in designing for both immediate needs and future flexibility, focusing on metadata foundations, tiered storage strategies, flexible computation models, and robust governance throughout the feature lifecycle.