Apache Spark: Computational Paradigms for Large-Scale Data Processing
Published on
by ![]() Gautham Vemulapalli
Gautham Vemulapalli
⏳ 7 min read
The increasing scale and complexity of data processing workloads has driven the evolution of distributed computing frameworks. In this analysis, I’ll examine Apache Spark’s architecture, application domains, and implementation patterns through the lens of real-world system design.
Spark’s Core Processing Paradigms
Spark’s versatility stems from its unified computational model that extends across multiple processing domains:
Batch Processing (Spark Core)
At its foundation, Spark’s RDD (Resilient Distributed Dataset) abstraction enables efficient batch processing through a declarative API that hides distribution complexity:
// Example: Simple word count implementation in Spark
val textFile = spark.sparkContext.textFile("hdfs://...")
val counts = textFile
.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
This paradigm excels in ETL pipelines that handle terabytes of data. A typical architectural pattern involves:
Data Sources → Kafka → Spark Jobs (transformation) → Data Warehouse
The internal execution flows through a DAG (Directed Acyclic Graph) scheduler that optimizes the execution plan, breaking complex transformations into stages separated by shuffle operations. This lazy execution model allows Spark to perform holistic optimizations rather than executing operations one at a time.
Stream Processing (Structured Streaming)
Spark’s stream processing extends the batch processing model with incremental computation, treating streaming data as a continuously growing table:
// Structured Streaming example
val streamingDF = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "broker1:9092")
.load()
val processedDF = streamingDF
.selectExpr("CAST(value AS STRING)")
.groupBy("value")
.count()
This enables near real-time processing architectures:
Event Sources → Kafka → Spark Streaming → State Store (Redis/Cassandra)
The micro-batch execution model balances throughput and latency constraints while maintaining exactly-once processing semantics. Unlike pure streaming systems like Flink, Spark’s approach treats streams as a series of small batches, providing higher throughput at the cost of slightly higher latency.
Machine Learning at Scale (MLlib)
Spark’s MLlib provides distributed implementations of common algorithms, enabling machine learning on datasets too large for traditional frameworks:
# Example: Distributed training of a recommendation model
from pyspark.ml.recommendation import ALS
# Create an ALS instance
als = ALS(
maxIter=5,
regParam=0.01,
userCol="userId",
itemCol="movieId",
ratingCol="rating"
)
A typical ML pipeline architecture with Spark might look like:
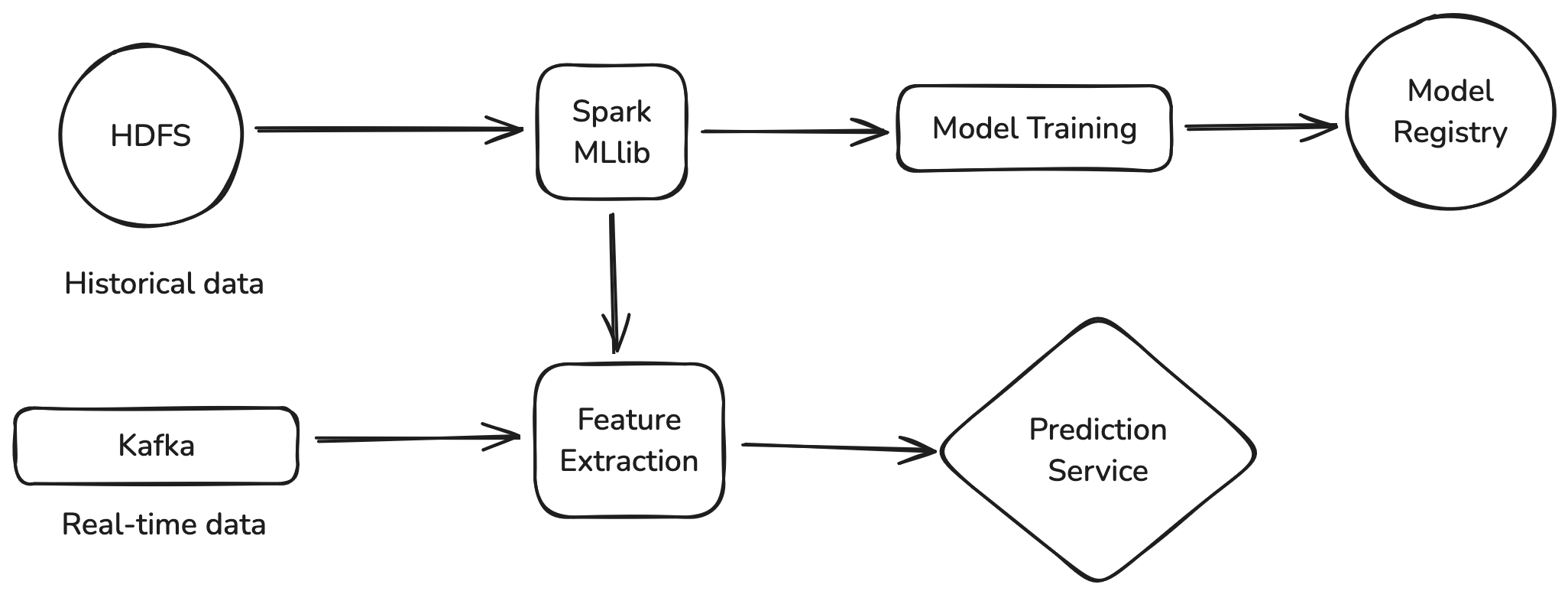
This unified approach allows data scientists to use the same framework for data preparation, feature engineering, and model training—reducing the cognitive overhead of switching between systems.
Architectural Advantages
Spark’s design offers several key advantages that explain its widespread adoption:
1. Horizontal Scalability
The framework’s architecture decouples compute from storage, enabling independent scaling of resources based on workload demands. Spark applications can scale from a single machine to thousands of nodes without changing the underlying application code, with performance typically scaling linearly with the addition of compute resources (up to the limits imposed by shuffle operations and data skew).
2. Fault Tolerance Mechanisms
Spark implements multiple layers of fault tolerance:
- RDD lineage: Tracks transformation history to rebuild lost partitions
- Checkpoint mechanisms: Persist intermediate state to durable storage
- Speculative execution: Relaunch slow tasks on different executors
This approach enables Spark to recover from node failures without data loss, a critical capability for long-running jobs processing terabytes of data across hundreds of nodes.
3. Unified Programming Model
The framework’s consistent API spans batch, streaming, and ML workloads:
// The same Dataset/DataFrame API works across paradigms
val batchDF = spark.read.json("s3://path/to/batch-data")
val streamDF = spark.readStream.json("s3://path/to/streaming-data")
This unification substantially reduces cognitive overhead and implementation complexity, allowing organizations to standardize on a single framework for diverse data processing needs.
Real-World Implementation Pattern: Recommendation System

Let’s examine a concrete implementation of a recommendation system architecture using Spark:
1. Candidate Generation
The initial stage identifies potential recommendation candidates through multiple approaches:
- Collaborative filtering: Identifies items frequently consumed together, implemented via Spark’s ALS algorithm
- Content-based filtering: Matches user preferences to item metadata
- Popularity-based recommendations: Suggests trending items for cold-start scenarios
These methods generate a pool of candidates that is significantly larger than the final recommendation set, providing diverse options for the ranking phase.
2. Feature Engineering Pipeline
The feature pipeline processes user, item, and contextual features:
- User features: Interaction history, demographic information, device usage patterns
- Item features: Metadata, popularity metrics, categorical attributes
- Context features: Time of day, device type, network conditions
Spark’s DataFrame API enables concise expression of complex feature transformations that can be applied consistently across training and inference paths.
3. End-to-End Data Flow Implementation
The system architecture includes both offline and online processing:
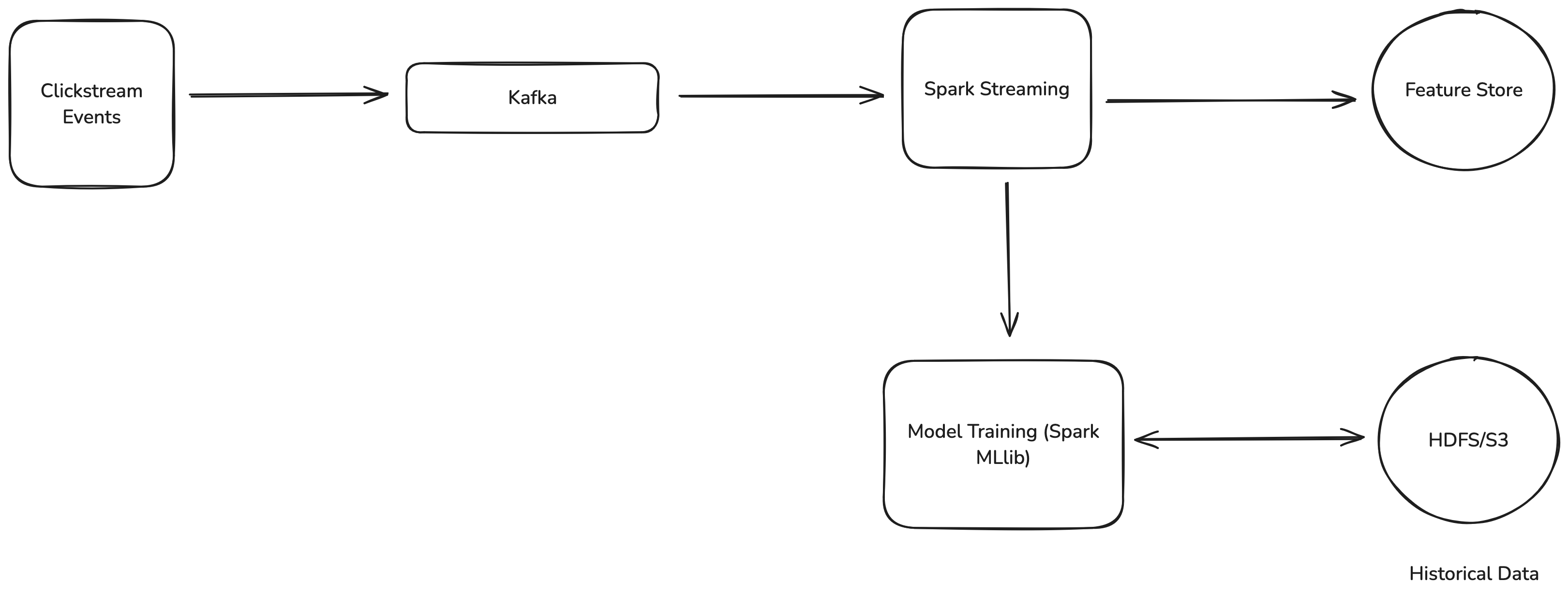
This architecture separates the high-throughput event processing path (for capturing user interactions) from the computationally intensive model training path, while ensuring that both paths operate on a consistent feature representation.
4. Model Training and Serving
The batch training component utilizes Spark’s ML capabilities for hyperparameter tuning, cross-validation, and model evaluation. Once trained, models can be:
- Deployed to a specialized model serving system like TensorFlow Serving
- Used within Spark itself for batch inference
- Exported to embedded models for edge deployment
This flexibility allows the same modeling approach to serve diverse inference scenarios, from offline batch scoring to real-time recommendations.
Architectural Considerations and Tradeoffs
When implementing Spark-based systems, several critical tradeoffs emerge:
1. Memory vs. Disk Usage
While Spark excels at in-memory processing, real-world implementations must balance RAM utilization with persistence:
- Memory-intensive operations: Caching, broadcast joins, window functions
- Disk spill behavior: When memory pressure exceeds thresholds
- Off-heap memory management: For large working sets
The optimal configuration depends on the workload characteristics, with interactive analytics favoring memory optimization and batch processing often prioritizing stability through conservative memory settings.
2. Batch Size vs. Latency
Particularly in streaming contexts, larger micro-batches improve throughput but increase latency:
- Small batches (100ms-1s): Lower latency, higher overhead, useful for real-time dashboards
- Medium batches (1s-30s): Balanced approach for most streaming applications
- Large batches (30s+): Highest throughput, suitable for near-real-time analytics
This fundamental tradeoff means that Spark Streaming is typically best suited for applications with latency requirements in seconds rather than milliseconds.
3. Operational Complexity
As Spark deployments scale, operational concerns become increasingly important:
- Resource management: Balancing memory, CPU, and I/O across applications
- Dynamic allocation: Adapting resource usage to changing workloads
- Monitoring and observability: Tracking execution metrics and bottlenecks
Modern deployment platforms like Kubernetes help address these challenges, but they introduce their own complexity in terms of configuration and management.
Deployment Models
Spark supports multiple deployment models, each with distinct characteristics:
- Standalone cluster: Simplest deployment, ideal for dedicated Spark environments
- YARN integration: Common in Hadoop environments, enables resource sharing
- Kubernetes deployment: Modern approach offering containerization and isolation
- Cloud-native services: Managed solutions like AWS EMR, Databricks, or Google Dataproc
The choice between these models depends on organizational constraints, existing infrastructure, and operational expertise. Cloud-native services reduce operational burden but may limit customization options.
When to Use Spark
Spark is particularly well-suited for:
- ETL and data transformation pipelines processing terabytes of data
- Interactive analytics on large datasets where sub-second response isn’t required
- Unified batch and stream processing with consistent semantics
- Large-scale machine learning where data exceeds single-machine capacity
These capabilities make Spark an excellent choice for data warehousing pipelines, feature engineering for ML systems, and analytical workloads that require complex transformations across diverse data sources.
When to Consider Alternatives
Despite its versatility, Spark isn’t ideal for all workloads:
- Sub-second query latency: Traditional databases or specialized analytics engines like ClickHouse offer better performance for interactive queries
- Millisecond-level streaming: Apache Flink or Kafka Streams provide lower latency for real-time processing
- Graph processing at extreme scale: Specialized graph databases or processing systems may offer better performance
- Simple ETL operations: For straightforward transformations, lighter-weight tools may have lower overhead
Recognizing these limitations helps teams avoid applying Spark to problems where simpler or more specialized tools would be more effective.
Conclusion
Apache Spark represents a powerful unified computing platform for large-scale data processing. Its strength lies in providing consistent abstractions across batch, streaming, and ML workloads while maintaining the scalability and fault tolerance required for production systems.
The most successful Spark implementations recognize both its capabilities and limitations, applying it to problems where its unified programming model and scalable execution engine provide genuine value while complementing it with specialized systems for workloads outside its sweet spot.
As data volumes continue to grow, frameworks like Spark that can efficiently orchestrate distributed computation across diverse processing paradigms will remain essential components of modern data infrastructure.